When to Think
When to Look
Uncertainty-Guided Lookback for Vision–Language Models

Uncertainty-Guided Lookback for Vision–Language Models
TL;DR More test-time thinking is not always better for vision–language models — long chains often drift away from the image and underperform plain instruct decoding. We replay every reasoning step under three visual conditions (real image, noise, none) to detect when the chain stops looking, then introduce uncertainty-guided lookback: a training-free decoder that injects a short image-anchoring prompt only when grounding is lost. Result: +2–3 pts Pass@1 on MMMU-val while using ~35–45% fewer thinking tokens, with consistent gains on five additional benchmarks.
o1, R1, and a generation of "thinking" models showed that more test-time compute, spent on explicit chains of thought, reliably lifts accuracy on reasoning-heavy benchmarks. The recipe was simple, scalable — and seductive.


more compute + more thinking → better reasoning?
In early 2025 a wave of methods ported the thinking recipe into vision-language models, falling into four families. The recipe was everywhere — and everyone hoped it would generalize from text to vision.
 LLaVA-CoT
LLaVA-CoT
 LLamaV-o1
LLamaV-o1
 InternVL2.5-Reasoner
InternVL2.5-Reasoner
 Mulberry
Mulberry
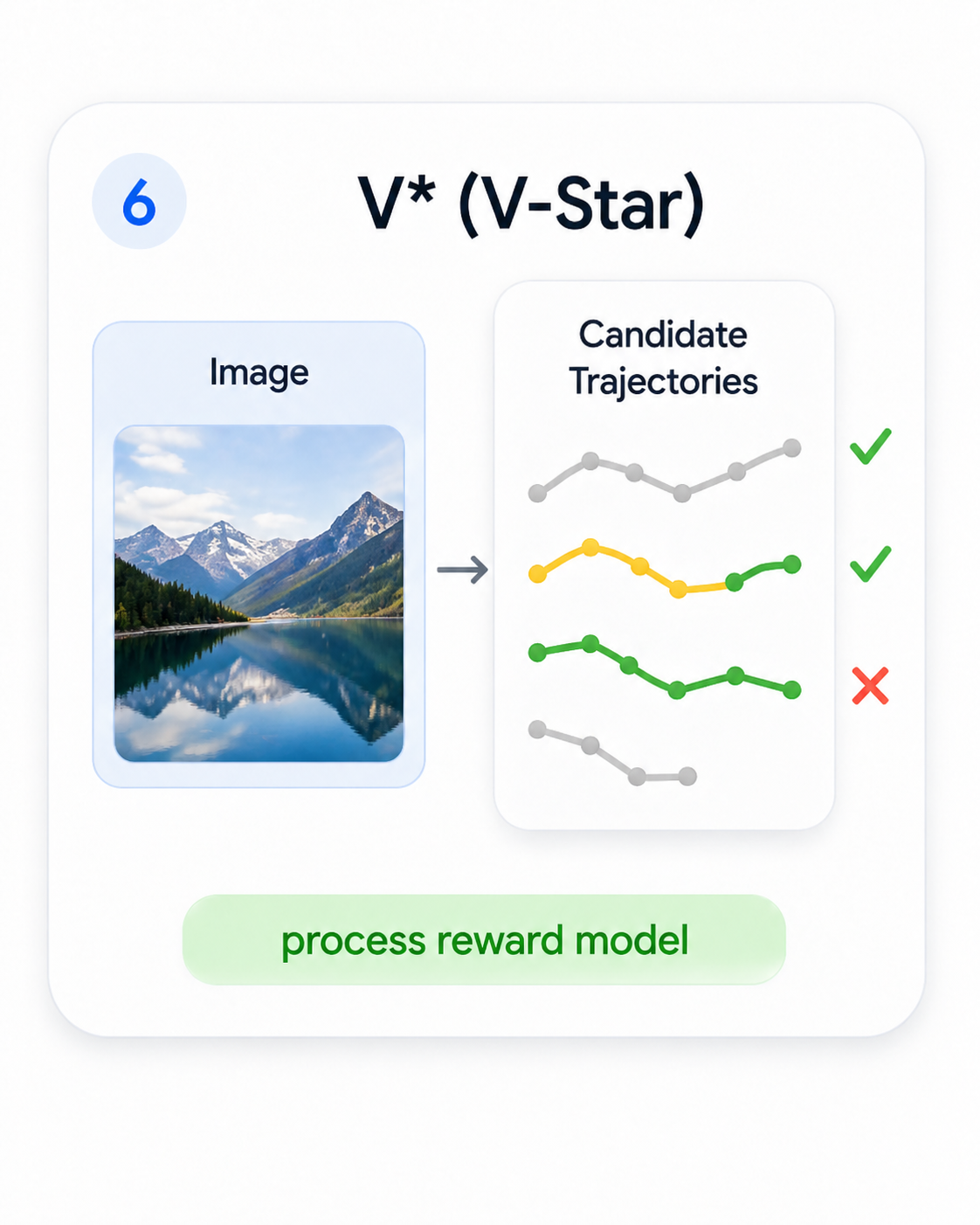 V-Star
V-Star
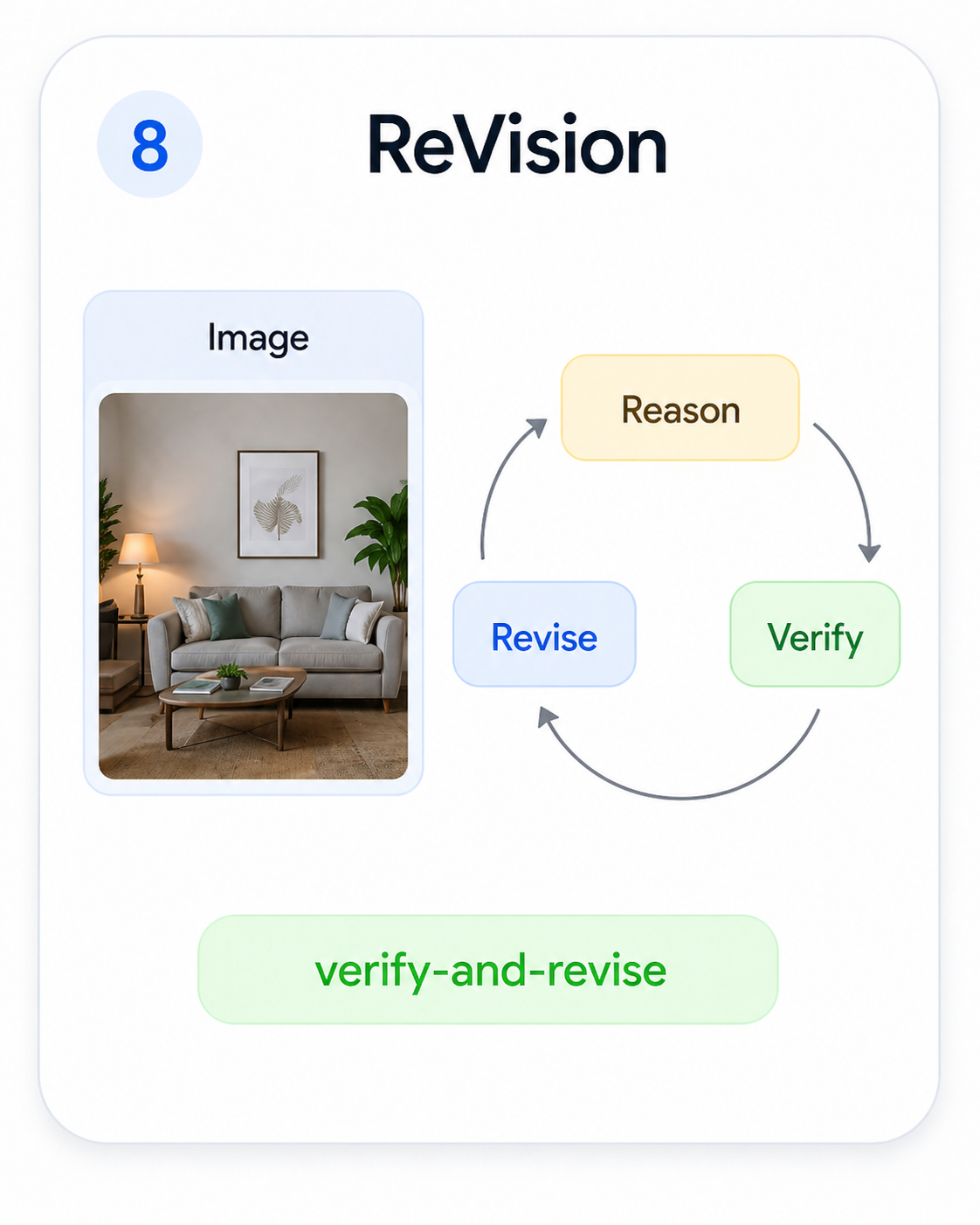 ReVision
ReVision
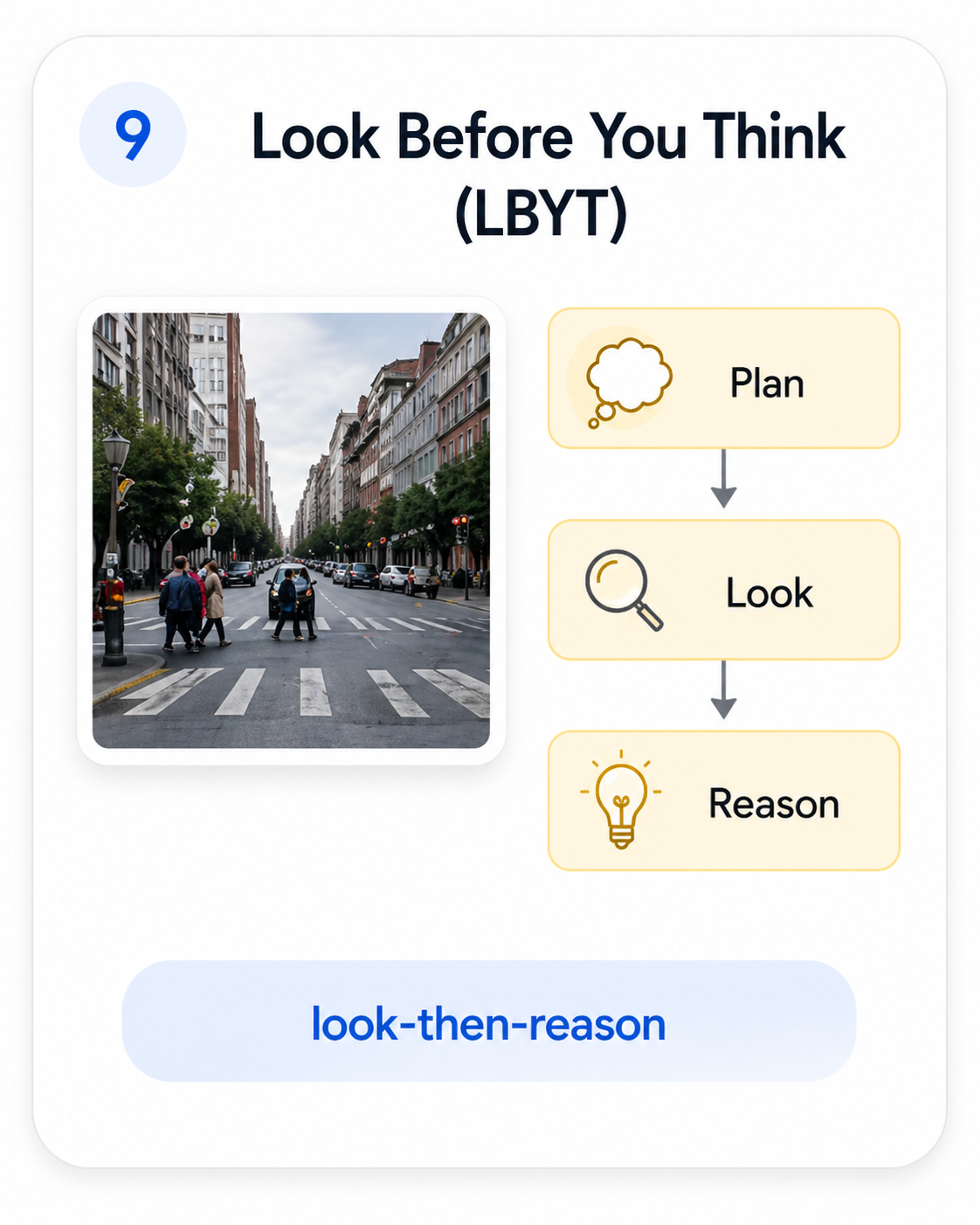 Look-Before-You-Think
Look-Before-You-Think
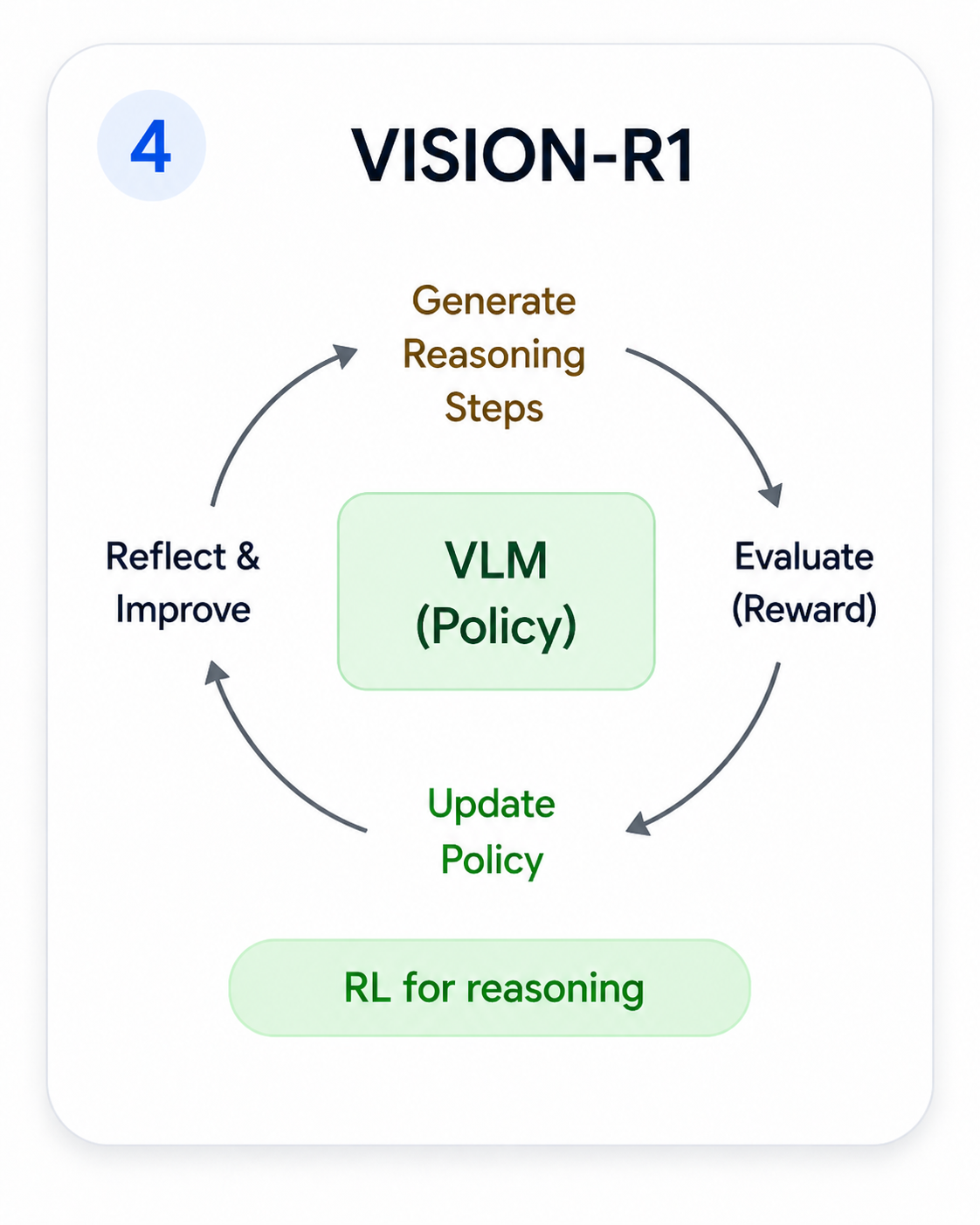 Vision-R1
Vision-R1
 R1-VLM
R1-VLM
 Charmer
Charmer
By mid-2025 a different question started to dominate: the trace looks like reasoning, but is the model actually reasoning? Recent papers documented that LVLMs inherit text-side failure modes and add new ones — over-reliance on text priors, visual hallucination, fluent chains that quietly stop using the image.


Looks like reasoning. Format ≠ faithfulness.
We focus on InternVL3.5 and Qwen3-VL — two leading open-source families that share the Qwen3 reasoning backbone but differ in their visual front-ends (InternViT vs. Qwen3-VL Vision) and connectors. Same reasoner, different eyes — exactly what we need to ask whether thinking actually helps visual reasoning.
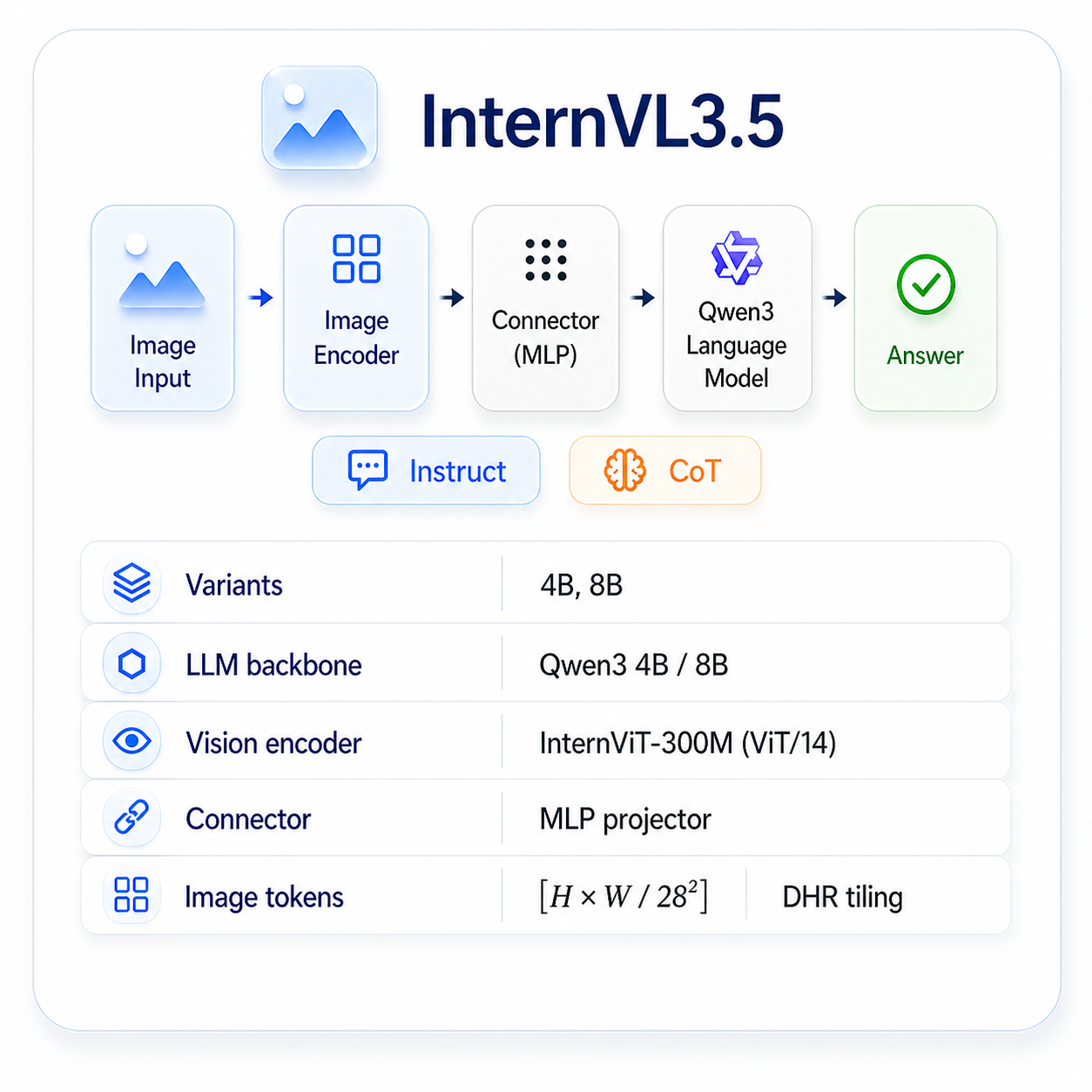
InternViT vision encoder, MLP connector, Qwen3 LLM backbone. Native Thinking mode toggled by a single official reasoning prompt.

Qwen3-VL Vision encoder, DeepStack connector, same Qwen3 LLM backbone. Thinking is gated by the official <think> token.
Across model sizes and sampling budgets, do thinking modes systematically beat instruct, or is the picture more complicated?
Should test-time compute go into longer chains (depth) or more sampled paths (breadth)? When does each shape pay off?
Is there a signal that tells the model — and us — that a chain has stopped looking at the image, before it derails?
Pass@k rises steeply from k=2 to k=6 and tapers past k=8 for every variant we test. Smaller models gain disproportionately — with enough breadth, a 4B model partially closes the gap to a 32B baseline.
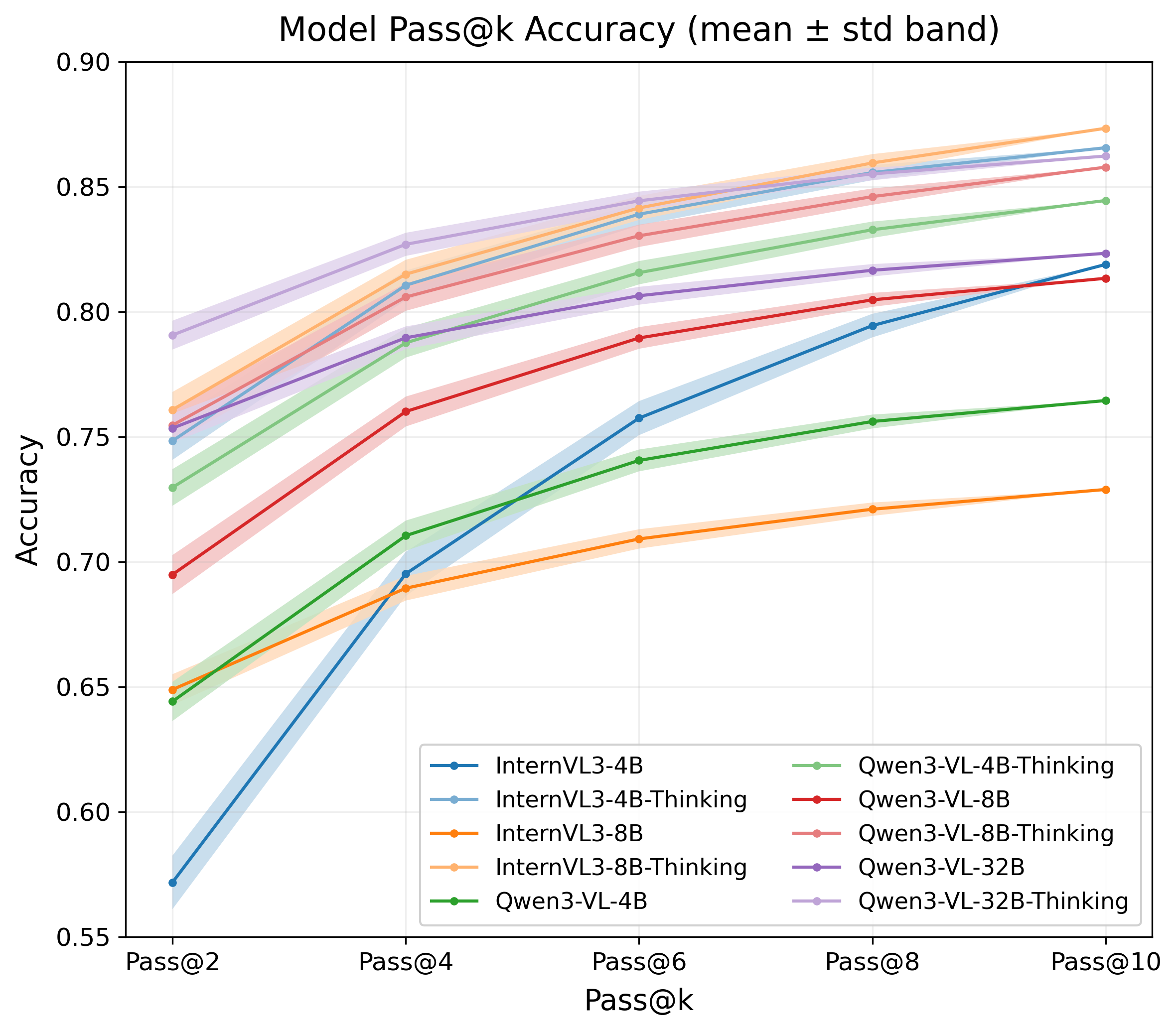
Each curve is one of ten LVLM variants on MMMU-val. The big lift always sits between two and six samples; after that, more breadth barely moves the needle, and turning Thinking on doesn't always beat plain instruct.
Breadth helps the model search. It does not fix grounding.
Reasoning-centric domains warm up under Thinking; recognition-centric domains often prefer concise instruct, where longer chains mainly introduce noise. Depth must be allocated, not always-on.
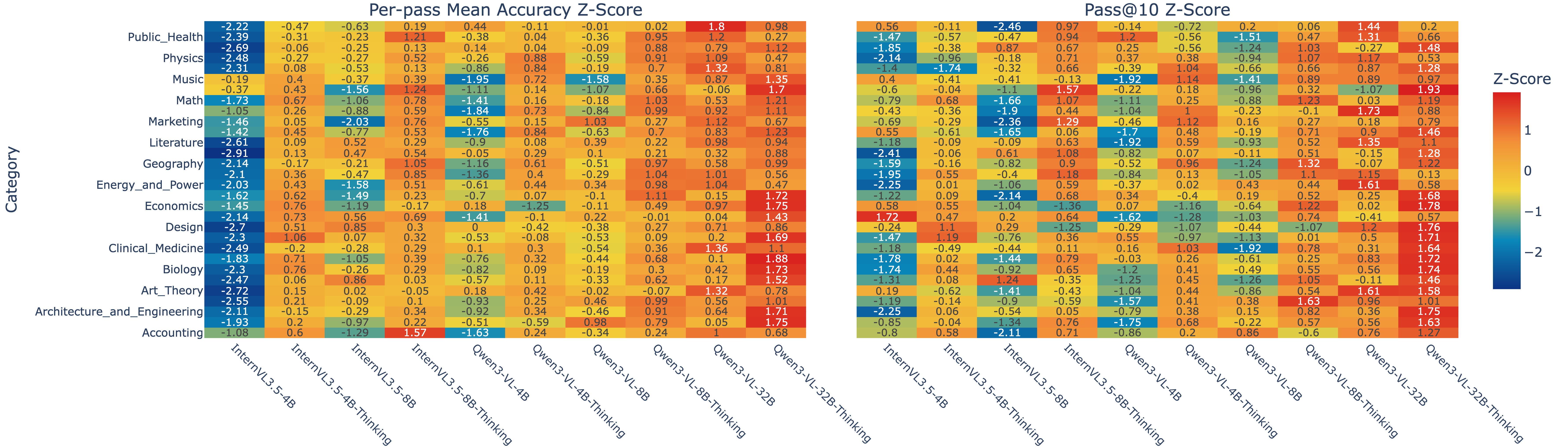
Z-scored accuracy across MMMU's thirty categories. Physics, math, engineering, chemistry and clinical rows warm up the moment Thinking is enabled. Literature, art, history and social-science rows often run cooler — the long chain just adds noise.
A 32B Thinking model fails on all 10 sampled passes; the same checkpoint in instruct mode answers correctly in a single token. The chain reads coherently — but it untethers from the picture, and every sampled path drifts the same way.
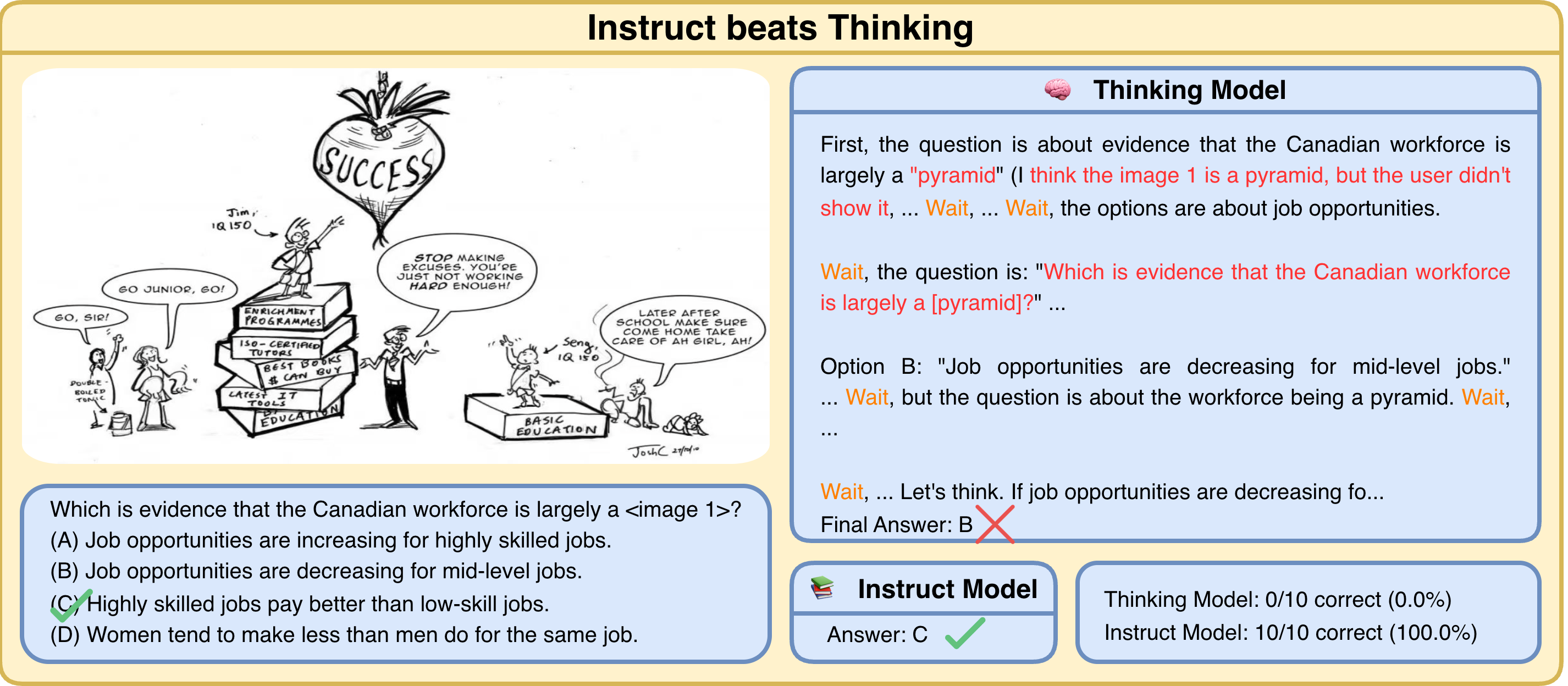
Same image, same model, two decoding modes. Thinking writes long, fluent, wrong reasoning ten times in a row. Instruct reads the picture and answers in one token.
The right question is not "how long?" but "is the chain still looking?"
Thinking roughly doubles tokens on Easy questions at 4B and 8B — exactly where the accuracy gain is smallest. Failed traces are as long as successful ones. Token count is not the hidden variable.
Tokens per question, split by mode, family, size and difficulty. The biggest cost of Thinking lands on Easy questions at small scale — the regime where the accuracy lift is smallest. At 32B the boxes finally tighten.
Two failure modes share one root cause — long-wrong on small models, quiet-wrong on large ones. Both are lost grounding.
Token-level $\Delta$PPL reveals the hidden variable. Correct trajectories show frequent, sharp dips in image-conditioned PPL — moments clustered around short phrases that explicitly return the chain to the picture. Wrong trajectories show fewer, shallower dips.
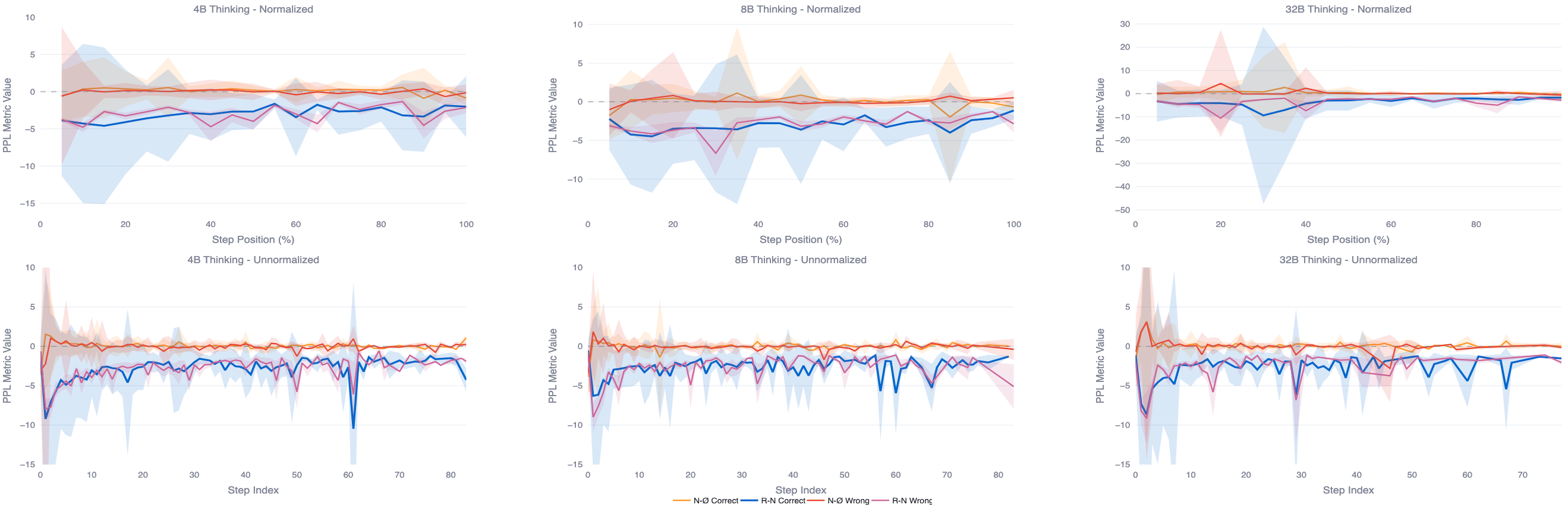
The blue curves are correct chains, the magenta are wrong ones. Negative spikes mean the real image just made the next token easier to predict — a moment of being grounded. The blue curves keep spiking. The magenta curves quietly flatline.
Good reasoning keeps being helped by the actual image. Bad reasoning forgets it.
We replay each reasoning step under three visual contexts and measure how the image affects token prediction. The probe gives us a per-step signal that length alone cannot: how much each next-token decision actually depends on the picture.
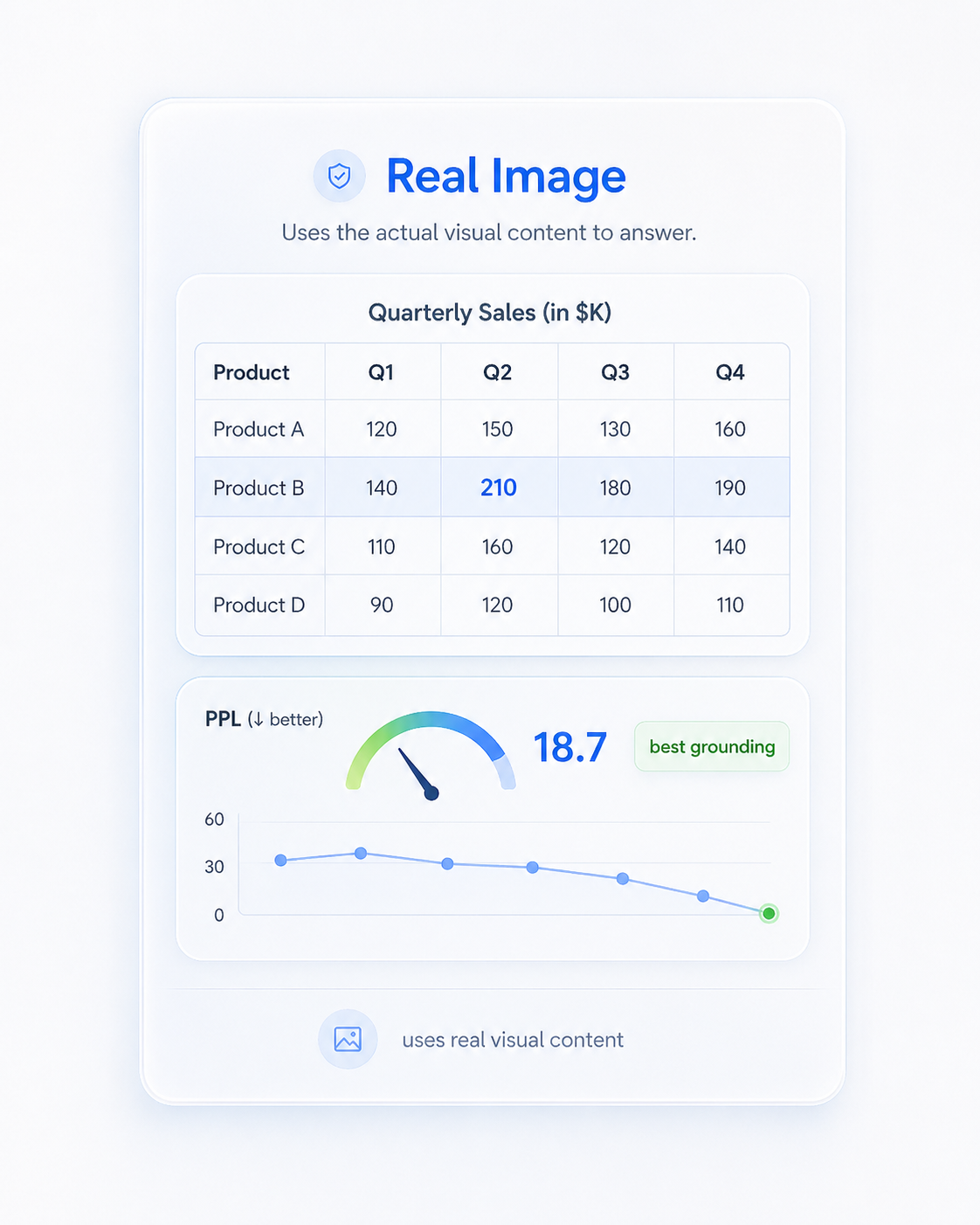
The model's actual visual input. Successful reasoning keeps drawing on it.
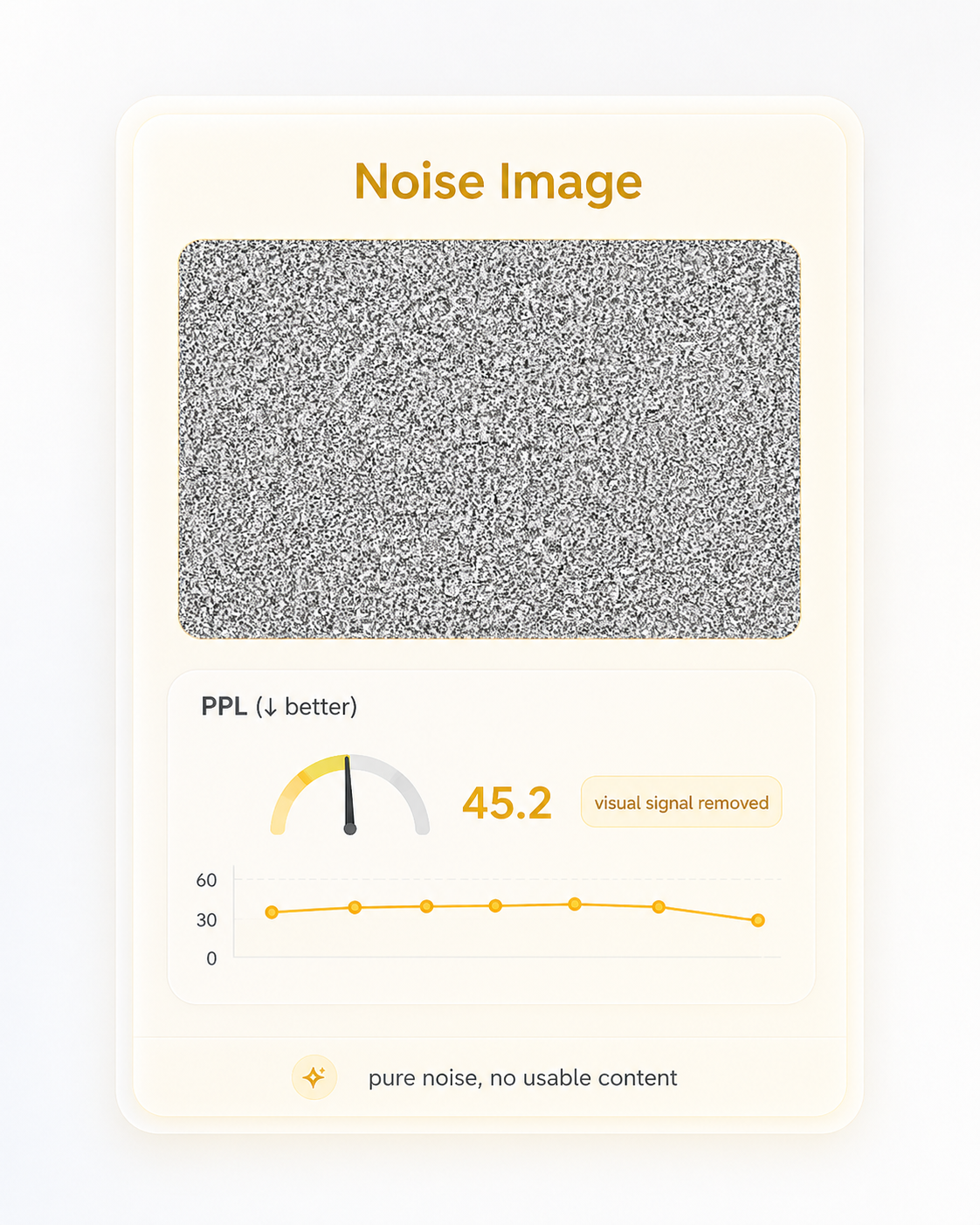
Same shape, semantically empty. Isolates the effect of any image being present.
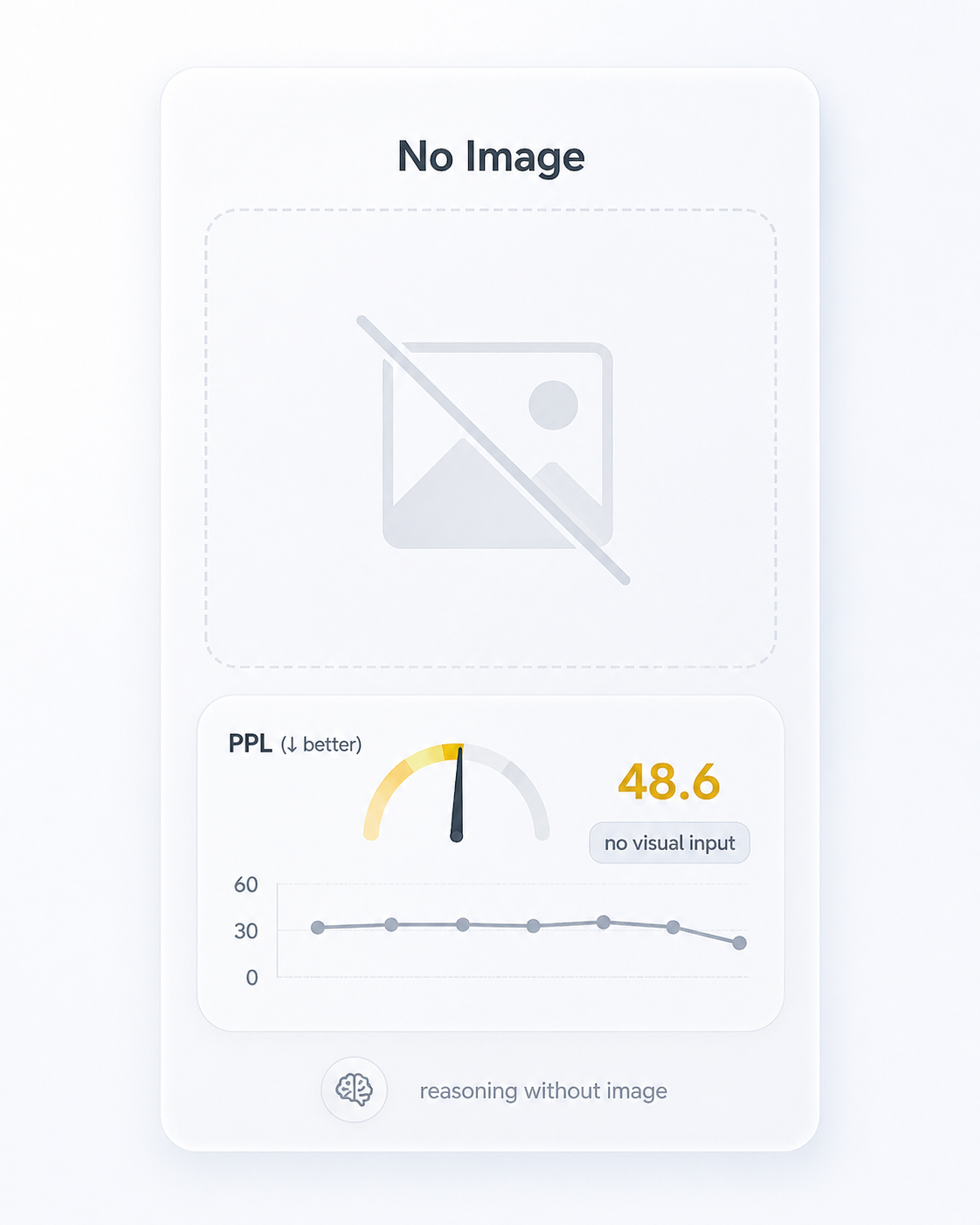
Text only. The pure language-prior baseline.
Two contrasts drop out. The first measures whether real visual content helps next-token prediction; the second isolates the effect of merely having an image present:
$$ \Delta_{\text{content}}(s) = \text{PPL}_{R}(s) - \text{PPL}_{N}(s) \quad\quad\quad \Delta_{\text{presence}}(s) = \text{PPL}_{N}(s) - \text{PPL}_{\varnothing}(s) $$
Steps with large $|\Delta_{\text{presence}}|$ but small $|\Delta_{\text{content}}|$ behave like generic "there is an image here" reactions — a probe for visually uncertain moments. Steps with strongly negative $\Delta_{\text{content}}$ in correct traces mark where the chain is actively grounded — the seeds for our lookback templates.
Mining the steps where $\Delta_{\text{content}}$ is most negative in correct traces yields a compact vocabulary of lookback phrases — multi-token templates that explicitly redirect the chain back to the image. Combined with reflection-style uncertainty markers ("wait", "hmm"), they give a lexical proxy for the perplexity signal that runs entirely online.
89% of mined phrases align with high-uncertainty steps — the lexical trigger and the perplexity-based cue independently agree on where the chain is losing its grip on the image.
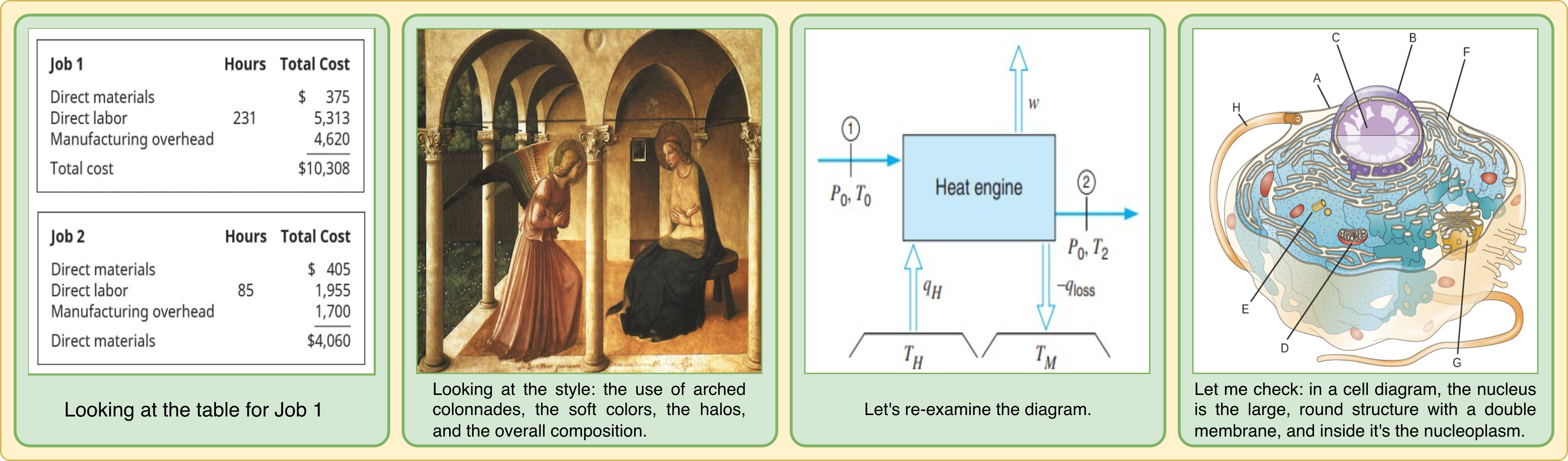
Real chains we mined where a short reflection sentence pulled the model back to the picture — a diagram, a table, a chart, a biology figure. The sentence is the moment grounding came back.
At test time, our controller wraps the model's native autoregressive decoding. Let $\mathcal{P}$ denote the pause-phrase vocabulary mined from steps with large $|\Delta_{\text{presence}}|$ and small $|\Delta_{\text{content}}|$, and let $\mathcal{L}$ denote the lookback templates mined from steps with strongly negative $\Delta_{\text{content}}$ in correct traces. At step $t+1$:
$$ y_{1:t+1}' = \begin{cases} y_{1:t}\,\Vert\, y_{t+1}\,\Vert\,\ell, & \text{if } \neg\,\text{ans}(t),\, \neg\,\text{trig}(t),\, \text{suffix}_{L}(y_{1:t+1}) \in \mathcal{P} \\[4pt] y_{1:t}\,\Vert\, y_{t+1}, & \text{otherwise} \end{cases} $$
Whenever the recent suffix matches a pause phrase from $\mathcal{P}$ and the model is still in the thinking phase, we append a lookback template $\ell \in \mathcal{L}$ — forcing an explicit re-consultation of the image before reasoning proceeds. To prevent degeneration, we allow at most one lookback within any window of $L$ thinking tokens, and disable triggers once the final-answer phase begins. All heavy computation (mining $\mathcal{P}$ and $\mathcal{L}$) is done offline; at inference time, the controller reduces to efficient $n$-gram matching plus occasional short prompt insertion.
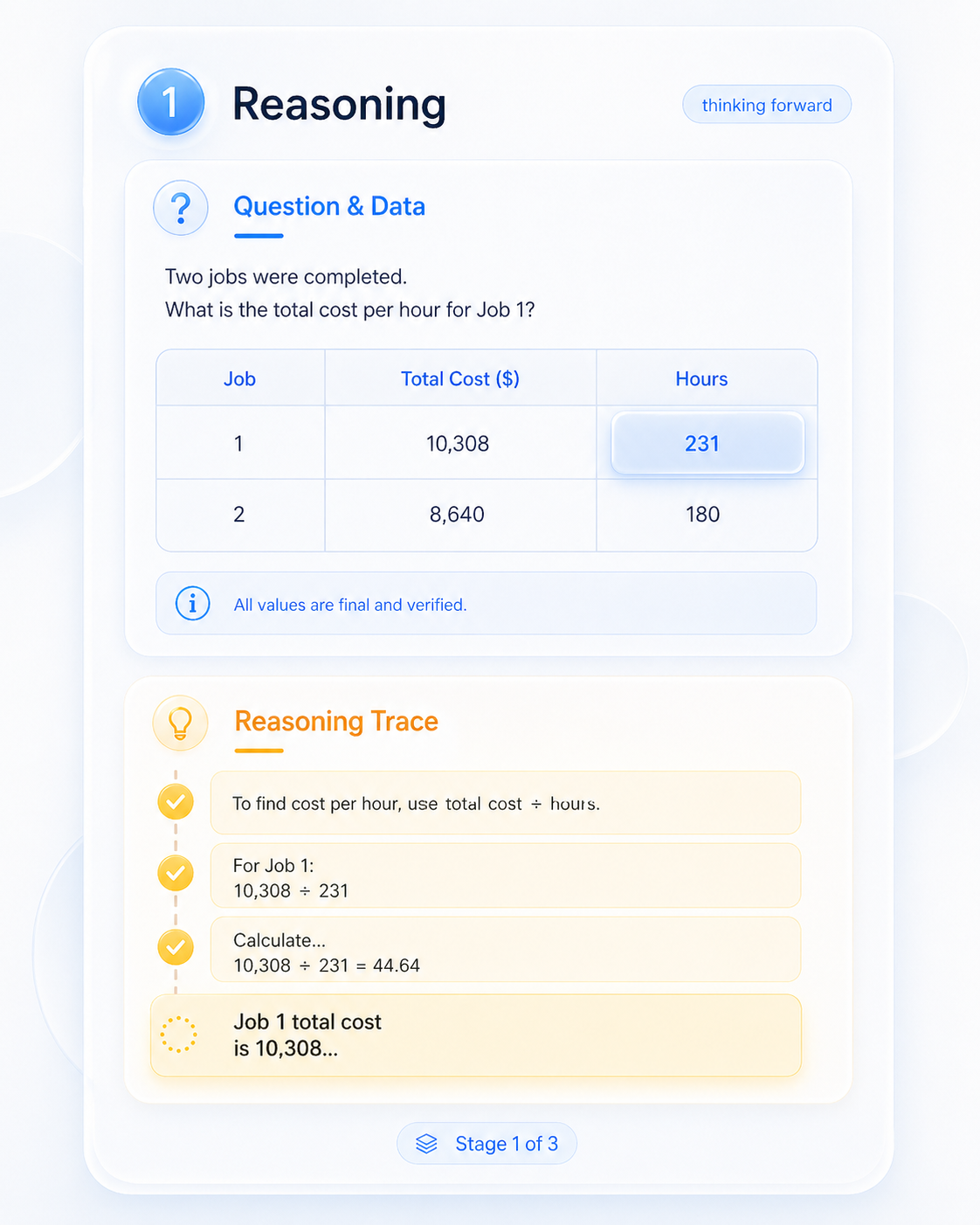
The VLM runs its native thinking pass. We track the per-step token probabilities the model is already producing — no reward model, no fine-tuning, no extra forward passes.
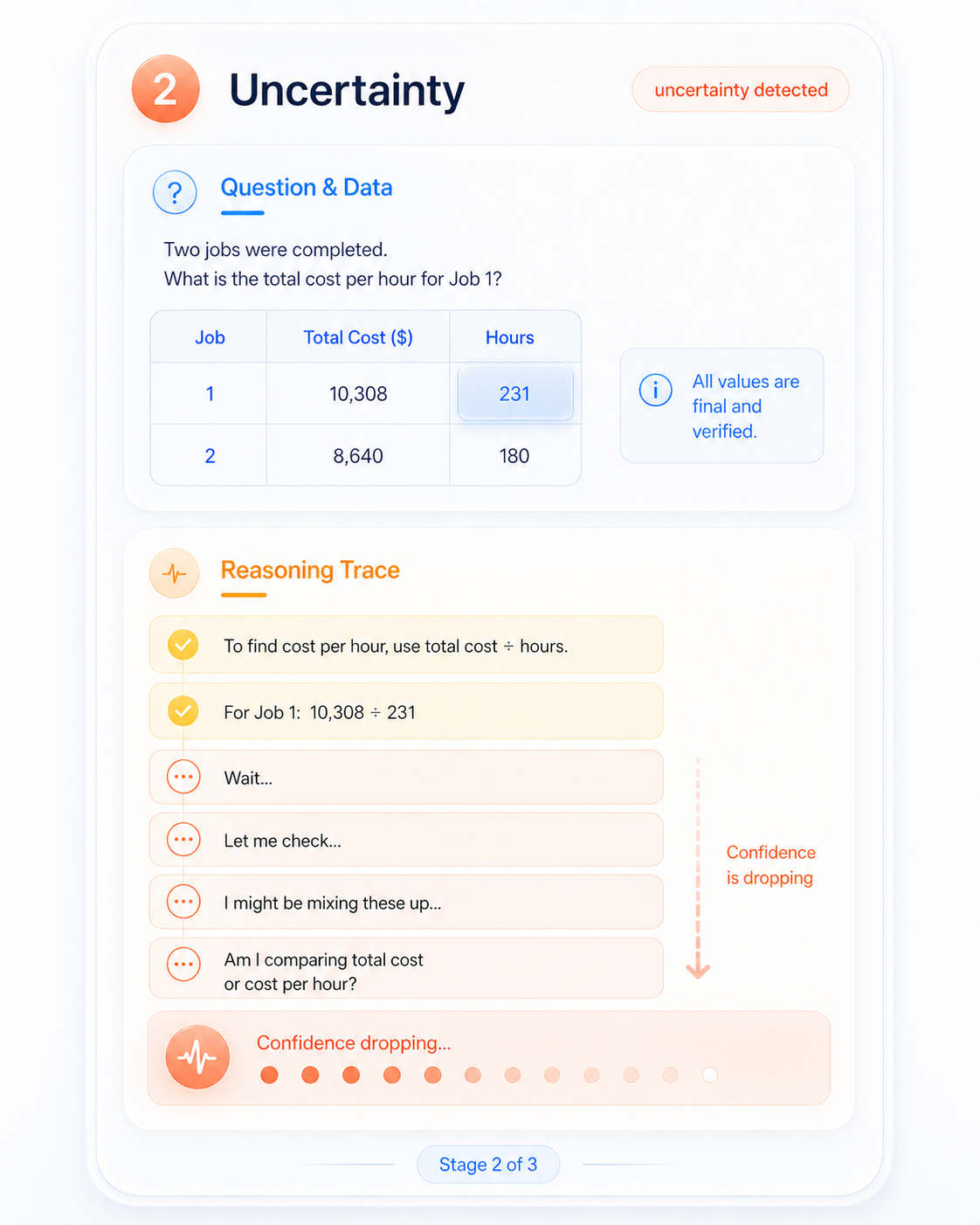
When token confidence drops and pause phrases ("wait", "hmm") appear in the suffix — the regime where 89% of our mined uncertainty phrases concentrate — we mark the chain as visually losing its grip.
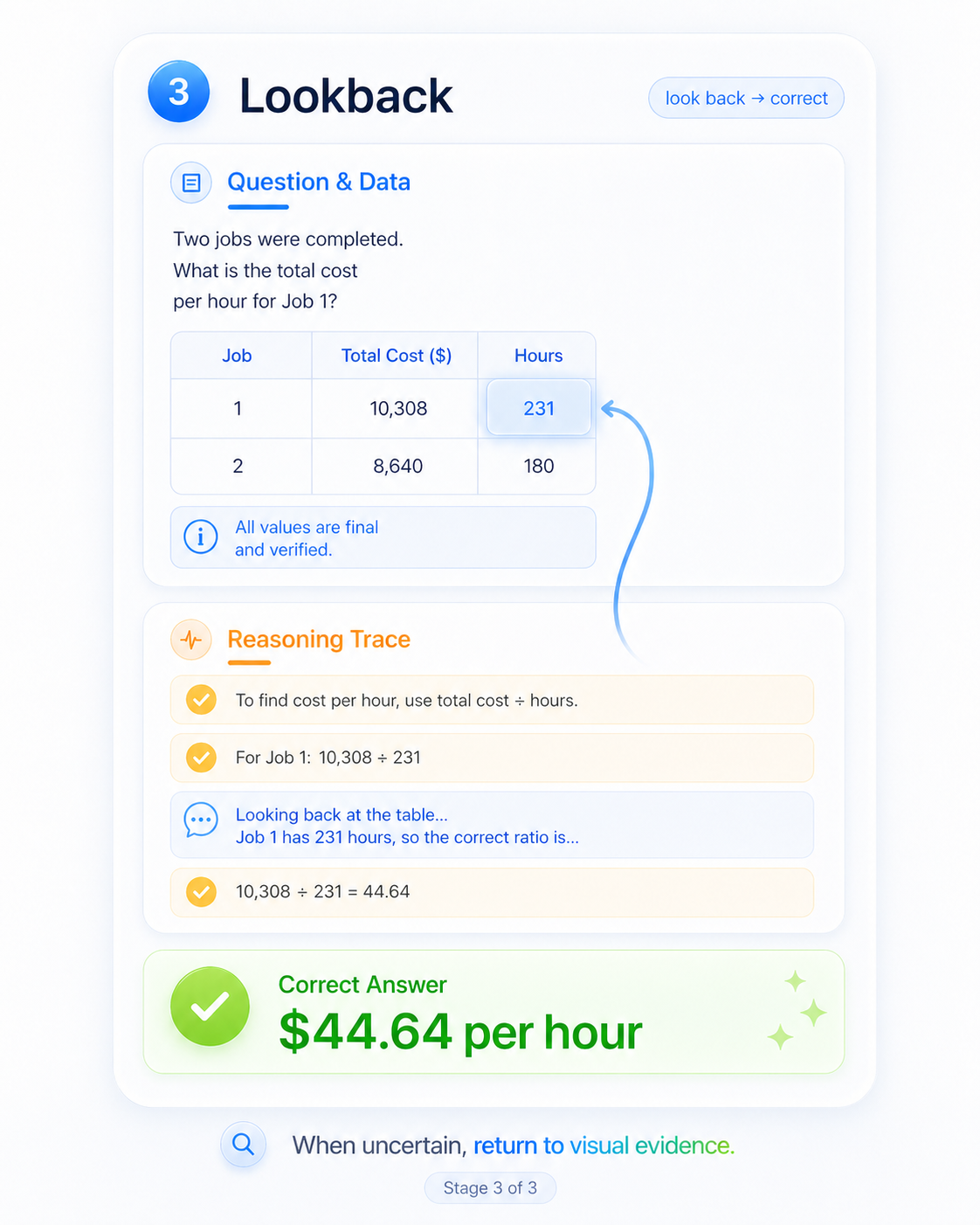
We inject a learned lookback prompt: "Looking back at the image, …". Image-conditioned PPL drops sharply on the next tokens; the model re-grounds and resumes from a state tied to the picture.
Reason → Detect → Look back. Training-free · any VLM · any budget.
The same probe can also choose which branch to follow. When a lookback fires at step $s$, we sample $M$ short continuations of horizon $H$ and score each by an aggregate visual-helpfulness term:
$$ \mathcal{V}^{(m)} = -\frac{1}{H}\sum_{t=s}^{s+H-1} \Delta_{\text{content}}^{(m)}(t) $$
Larger $\mathcal{V}^{(m)}$ corresponds to trajectories where the real image consistently lowers token loss compared to noise. We continue from the branch with maximal $\mathcal{V}^{(m)}$. Because lookback events are rare and localized, parallel sampling adds only modest overhead — yet substantially raises the chance that at least one branch is tightly grounded in the image.
On MMMU-val and five other vision–language benchmarks, uncertainty-guided lookback raises accuracy and cuts token spend at the same time — a combination that's rare for inference-only methods. The full per-size and per-category numbers live in the paper; the figures below tell the shape of it.

On MMMU-val, lookback shifts every model up the accuracy axis and to the left on tokens — the kind of move that's rare for inference-only methods. The largest gains land in domains where standard Thinking was weakest.

The same controller, no retuning, transfers to math-focused suites (MathVista, MathVision, MathVerse), broad multimodal suites (MMBench, MMStar), and to InternVL3.5-Think — the effect targets a shared LVLM behavior rather than a Qwen-specific quirk.
@inproceedings{bi2026lookback,
title = {When to Think and When to Look: Uncertainty-Guided Lookback},
author = {Bi, Jing and Bellos, Filippos and Guo, Junjia and Li, Yayuan and
Huang, Chao and Tang, Yunlong and Song, Luchuan and
Liang, Susan and Zhang, Zhongfei and Corso, Jason J. and
Xu, Chenliang},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR)},
year = {2026}
}